P2L1 - Process and Process Management¶
1 - Lesson Preview¶

One of the key abstractions that operating systems support is that of a process. In this lecture, I will explain what is a process, how an operating system represents a process, and also what an operating system must do in order to manage one or more processes, particularly when multiple processes share a single physical platform. Before we begin, let’s define what a process is. In the simplest terms, a process is an instance of an executing program. Sometimes it makes sense to use the terms task or job interchangeably with a process.
2 - Visual Metaphor¶


We will use again a visual metaphor to describe what a process is. Continuing with a toy shop as an example, you can think of a process as an order of toys. An order of toys has its state of execution, it requires some parts, and a temporary holding area, and even may require some special hardware. For instance, it’s state of execution, may include the completed toys, the toys that are waiting to be built, that are part of that order, and other things. Building the toys may require various parts, like plastic pieces, wooden pieces, and these come in different containers, or we may require some other temporary holding area for the pieces. And, finally, to actually build a toy, we may need some special hardware. We may need sewing machines, glue guns, or other types of tools. So, how does all of this then compare to a process in an operating system? Well, a process also has a state of execution described with the program counter, the stack pointer. All this information is used by the operating system to decide how to schedule the process, how to swap between multiple processes, and for other management tasks. In order to execute, the process needs some data. There’s some state in registers. And, it also has some temporary holding area. For instance, it occupies state in memory. Finally, executing a process may require some special hardware like I/O devices like discs, or network devices. The operating system has to manage these devices and control which of the processes that are perhaps executing concurrently at the same time gets access to which hardware components. This is similar to what would happen in a toy shop where the toy shop manager has to control how the special hardware, like the sewing machine or the glue gun, are used. Which particular order of toys will get to be assigned the usage of these more designated hardware components.
3 - What is a Process?¶


Let’s talk now, more specifically, about processes. And, we’ll start first by understanding, what is a process? To do this, recall that one of the roles of the operating system is to manage the hardware on behalf of applications. An application is a program that’s on disk, in flash memory, even in the cloud. But it’s not executing, it’s a static entity. Here, for instance, in this picture, we have some application that’s stored on disk. Once an application is launched, it’s loaded in memory here, and it starts executing. Then it becomes a process. So a process is an active entity. If the same program is launched more than once, then multiple processes will be created. These processes will executing the same program, but potentially will have very different state. In fact, very likely they will have very different state. For instance, a process can be one instance of the word editor program. Here, you’re displaying some notes from a previous lecture. And perhaps you’re just reviewing it, you’re not really modifying this. And then you can have a second process, another instance of the exact same word editor program to take notes from this lecture. Given that we just started, this probably doesn’t have many notes, so it has relatively small state, and it may have some unsaved edits. So, process therefore represents the execution state of an active application. It doesn’t mean necessarily that it’s running. It may be waiting on input like user input to type in certain notes. Or it may be waiting for another process that’s currently running on the CPU, in case there’s just one CPU in the system.
4 - What Does a Process Look Like?¶

So what does a process look like? A process encapsulates all of this data for running application. This includes the code, the data, all of the variables that that application needs to allocate. Every single element of the process state has to be uniquely identified by its address. So an OS abstraction used to encapsulate all of the process state is an address space. This is what we have here. The address space is defined by a range of addresses from V0 to some Vmax, and different types of process state will appear in different regions in this address space. What are the different types of state in a process? First we have the code, the text, and the data that is available when the process is first initialized. So all of this is static state that’s available when the process first loads. Then during the execution, the process dynamically creates some state, allocates memory, stores them per our results, reads data from files. This part of the address space we call a heap. In this picture here, the heap is shown as contiguous portion of the address space starting immediately after the data, but in reality there may be holes in this space. It may not be contiguous. There may be portions of it that don’t have any meaning for that particular process and, in fact, the process isn’t even allowed to access them. I will talk in a little bit how the operating system knows what’s okay for the process to access versus what isn’t. Another very important part of the address space is what we call a stack. It’s a dynamic part of the address space state, in that it grows and shrinks during execution, but it does so in a last-in, first-out order. Whatever you put on the stack will be the very first item to be returned when you’re trying to read from the stack. Consider for instance we’re executing a particular portion of the process. And now we need to call some procedure to jump to a different part of the address space. We want to make sure that the state that we were in at this point of the execution, before we called this other procedure, is saved, and then that it will be restored once we come back from the execution. We can place the state on the stack and jump to execute this portion of the code. So the procedure y. When we’re finished with y, the state x will be popped from the stack and we can continue the execution in the same state that we were in before the call to y was made. There are lots of points during a process execution where the last-in, first-out behavior is very useful. So the stack is a very useful data structure.
5 - Process Address Space¶

As a whole, we refer to this process representation as an address space. We said earlier that the potential range of addresses from v0 to vmax represents the maximum size of the process address space. And we call these addresses virtual addresses. So these, between v0 and vmax are the addresses that are used by the process to reference some of its state. We call these addresses virtual, because they don’t have to correspond to actual locations in the physical memory. Instead, the memory management hardware and operating system components responsible for memory management, like page tables maintain a mapping between the virtual addresses and the physical addresses. By using this type of mapping, we decouple the layout of the data in the virtual address space, which may be complex and it may depend on the specifics of the application or the tools that we used, like how the compiler chose to lay that data out. That’s completely decoupled with how that data is laid out in physical memory. And that will allow us to maintain physical memory management simple and not in any way dictate it by the data layout or processes that are executing. For instance, the variable x may be at a location 03c5 in the virtual address space. And this may correspond to a completely different address, 0f0f in physical memory. The way this happens is when the process requests some memory to be allocated to it at a particular virtual address. The address of the physical memory that the operating system actually allocates may be completely different, and instead of notifying the process about the details of where exactly in memory that variable really is. The operating system will create a mapping between this virtual address, 03c5, and the physical address, 0f0f, where x actually is. So then whenever the process tries to access x, this mapping is referenced, and in reality the exact physical location where x is will be accessed. As long as the mapping between 03c5 and 0f0f is present in this mapping table, this is a page table and this is a page table entry, any access of the process to x will, in fact, access the correct physical location where x is stored.
6 - Address Space and Memory Management¶

We said already not all processes require the entire address space from V0 to VMax. There may be portions of this address space that are not allocated. Also, we may simply not have enough physical memory to store all this state even if we do need it. For instance, if we have virtual addresses that are 32 bits long, this address space can have up to 4 gigabytes. And if we have several such processes running at the same time, even in a pretty expensive machine, we will quickly run out of physical memory. To deal with this, the operating system dynamically decides which portion of which address space will be present where in physical memory. For instance, inside a system with processes P1 and P2, they may share the physical memory in this manner. So, the regions marked with yellow belong to P1, and the regions marked with pink belong to process P2. Both P1 and P2 may have some portions of their address space not present in memory but rather swapped temporarily on disk. And this portion of the address space will be brought in whenever it’s needed. And perhaps that will cause some other parts of either P1’s or P2’s address space to be swapped to disk to make room. So the operating system must maintain information where these virtual addresses actually are in memory, on disk since it maintains the mapping between the virtual addresses and the physical location of every part of the process address space. I will talk about memory management in a later lesson, but at the very least, you must understand that for each process, the operating system must maintain some information regarding the process address space. We mentioned the page tables for instance. And then the operating system uses this information to both maintain mappings between the virtual addresses and the physical location where the state is actually stored. And also to check the validity of accesses of memory to make sure that a process is actually allowed to perform a memory access.
7 - Virtual Addresses Quiz¶

To review this, let’s take a quiz. If two processes, P1 and P2, are running at the same time, what are the ranges of their virtual address space that they will have? The first choice is P1 has address ranges from 0 to 32,000, and P2 from 32,001 until 64,000. The second choice is that both P1 and P2 have address ranges from 0 to 64,000. And the last choice, P1 has an address space range from 32,001 to 64,000, and P2 has address ranges from 0 to 32,000. So the reverse from the first one. So go ahead and mark all the ones that you think are correct answers.
8 - Virtual Addresses Quiz Solution¶
The correct answer is the second one. Both P1 and P2 can have the exact same virtual address space range from 0 to 64,000 in this case. The operating system underneath will map P1’s virtual addresses to some physical locations, and P2’s virtual addresses to other physical locations. The fact that we have decoupled the virtual addresses that are used by the processes from the physical addresses where data actually is makes it possible for different processes to have the exact same address space range and to use the exact same addresses. The OS will make sure that they point to distinct physical memory locations if that’s what’s required.
9 - Process Execution State¶

For an operating system to manage processes, it has to have some kind of idea of what they are doing. If the operating system stops a process, it must know what it was doing when it was stopped so that it can restart it from the exact same point. So how does an operating system know what a process is doing? Let’s think about the underlying hardware, the CPU, and think how it executes applications. Applications, before they can execute, their source code must be compiled, and a binary is produced. The binary is a sequence of instructions, and they’re not necessarily executed sequentially. There may be some jumps, loops, or even there may be interrupts that will interrupt the execution of the binary. At any given point of time, the CPU needs to know where in this instruction sequence the process currently is. So we call this the program counter, PC. The program counter is actually maintained on the CPU while the process is executing in a register. And there are other registers that are maintained on the CPU. This whole value is necessary during the execution. They may have information like addresses for data. Or they may have some status information that somehow affects the execution of the sequence. So these are also part of the state of the process. Another piece of state that defines what a process is doing is the process stack. And the top of the stack is defined by the stack pointer. We need to know the top of the stack because we said the stack exhibits this last in, first out behavior, so whatever item was the last one to come on top of the stack needs to be the very first item that we can retrieve from the stack. But the stack pointer maintains this information. And similarly, there are other bits and pieces of information that help the operating system know what a process is actually doing at a particular point of time. To maintain all of this useful information for every single process, the operating system maintains what we call a process control block, or a PCB.
10 - Process Control Block¶

Let’s see now what is a Process Control Block. A Process Control Block is a data structure that the operating system maintains for every one of the processes that it manages. From what we saw so far, the Process Control Block must contain process state like the program counter, the stack pointer, really, all of the CPU registers, their values,uh, as they relate to the particular process, various memory mappings that are necessary for the virtual to physical address translation for the process, and other things. Some of the other useful information includes a list of open files, for instance, information that’s useful for scheduling, like how much time this particular process had executed in a CPU, how much time it should be allocated in the future. This depends on the process priority, etc. The Process Control Block data structure, or PCB as we call it, is created when the process is initially created itself. And it’s also initialized at that time. For instance, the program counter will be set to point to the very first instruction in that process. Certain fields of the process are updated whenever the process state changes. For instance, when a process requests more memory, the operating system will allocate more memory and will establish new valid virtual to physical memory mappings for this process. This will reflect the memory limits information as well as the information regarding the valid virtual address regions for this process. And this perhaps doesn’t happen too often. Other fields of this PCB structure change pretty frequently. For instance, during the execution of the program, the program counter changes on every single instruction. We certainly don’t want the operating system for every instruction that the process executes to have to spend time to write this new PCB value for the program counter. The way this is handled is that the CPU has a dedicated register, which it uses to track the current program counter for the currently executing process. This PC register will get automatically updated by the CPU on every new instruction. It is the operating system’s job, however, to make sure to collect and save all the information that the CPU maintains for a process, and to store it in the Process Control Block structure whenever that particular process is no longer running on the CPU.
11 - How is a PCB Used?¶

Let’s see what we mean by this. Let’s assume the operating system manages two processes, P1 and P2. It has already created them and their Process Control Blocks, and these Process Control Blocks are stored somewhere in memory. Let’s say P1 is currently running on the CPU, and P2 is idle. What this means, that P1 is running, is that the CPU registers currently hold a value that correspond to the state of P1. So, they will ultimately need to be stored in PCB of P1. Then at some point, the operating system decides to interrupt P1, so P1 will become idle. Now, what the operating system has to do, it has to save all the state information regarding P1, including the CPU registers, into the Process Control Block for P1. Next, the operating system must restore the state about process 2 so that process 2 can execute. What that means is that it has to update the CPU registers with values that correspond to those of the Program Control Block for process 2. If at some point during its execution, P2 needs more physical memory, it will make a request via the malloc call, for instance. And the operating system will allocate that memory and establish new virtual to physical address mappings for P2, and update as appropriate the control block data structure for process P2. When P2 is done executing, or when the operating system decides to interrupt P2, it will save all the information regarding P2 state in the Process Control Block for P2, and then it will restore the Process Control Block for P1. P1 will now be running, and the CPU registers will reflect the state of P1. Given that the value of the Process Control Block for P1 corresponds exactly to the values it had when we interrupted P1 earlier, that means that P1 will resume its execution at the exact same point where it was interrupted earlier by the operating system. Each time the swapping between processes is performed, the operating system performs what we call context switch.
12 - Context Switch¶

Recall our illustration that shows how the operating system swaps between P1 and P2 for them to share the CPU. In this illustration, the process control blocks for P1 and P2 reside in memory. And the values of the CPU will change depending on which process is currently executing. Now we can more formally state that a context switch is the mechanism used by the operating system to switch the execution from the context of one process to the context of another process. In our diagram, this is happening both when the operating system switches from the execution of P1 to the execution of P2. And then again a second time when the OS switches from the execution of P2 back to the execution of P1. This operation can be expensive, and that’s for two reasons. First, there are direct costs, and this is basically the number of cycles that have to be executed to simply load and store all the values of the process control blocks to and from memory. There are also indirect costs. When process 1 is running on the CPU, a lot of its data is going to be stored into the processor cache. As long as P1 is executing, a lot of its data is likely going to be present somewhere in the processor cache hierarchy. In the picture, we show a single processor cache, but in practice, modern CPUs have a hierarchy of caches from L1 to L2, down to the last level cache. And each one is larger, but potentially slower than the previous one. More importantly, however, accessing this cache is much, much faster than accessing the memory. For instance, the accesses along the processor cache hierarchy will be on the order of cycles, whereas the accesses to memory will be on the order of hundreds of cycles, for instance. When the data we need is present in the cache, in this case, that’s P1’s data, we call this that the cache is hot. But when we context switch to P2, some, or even all, of the data belonging to P1 in the cache will be replaced to make room for the data needed by P2. So, the next time P1 is scheduled to execute, its data will not be in the cache. It will have to spend much more time to read data from memory, so it will incur cache misses. We call this the cold cache. Running with a cold cache is clearly bad because every single data access requires much longer latency to memory and it slows down the execution of the process. As a result, we clearly want to limit the frequency with which content switching is done.
13 - Hot Cache Quiz¶

Here’s a quick quiz about the processor cache. For the following sentence, check all options that correctly complete it. The sentence start says, when a cache is hot, and here are the choices. When a cache is hot, it can malfunction, so we must context switch to another process. When a cache is hot most process data is in the cache, so the process performance will be at its best. Or, the last choice, when a cache is hot sometimes we must context switch
14 - Hot Cache Quiz Solution¶
The first option implies that the hot cache means that the cache is physically getting hot, then it will malfunction. However, the term hot cache has nothing to do with the actual temperature of the cache. It merely refers that many of the cache accesses will actually resolve in a cache hit. The data will be found and cached. So in this context, the more cache hits means that the cache is hot. Now coincidentally, this also will lead to a rise in temperature. However, the effects of that aren’t going to be that the operating system will context switch to another process. Modern systems and platforms do have a lot of mechanisms to deal with temperature rises, but that’s beyond the scope of this lecture. Let’s look at the second option. The second option is actually the most correct one. If data is present in the cache, it will be accessed much faster than if data is accessed from memory. So, executing with a hot cache actually corresponds to the state when the process performance is at its best. And unfortunately, three is correct as well. Although hot cache means best performance, sometimes we must context switch although the process cache is hot. And that’s because there is another process that maybe has higher priority that needs to execute. Or maybe we have a policy where we have to timeshare the CPU between two processes and P1’s time has expired, so we have to context switch and give the CPU to P2.
15 - Process Life Cycle: States¶

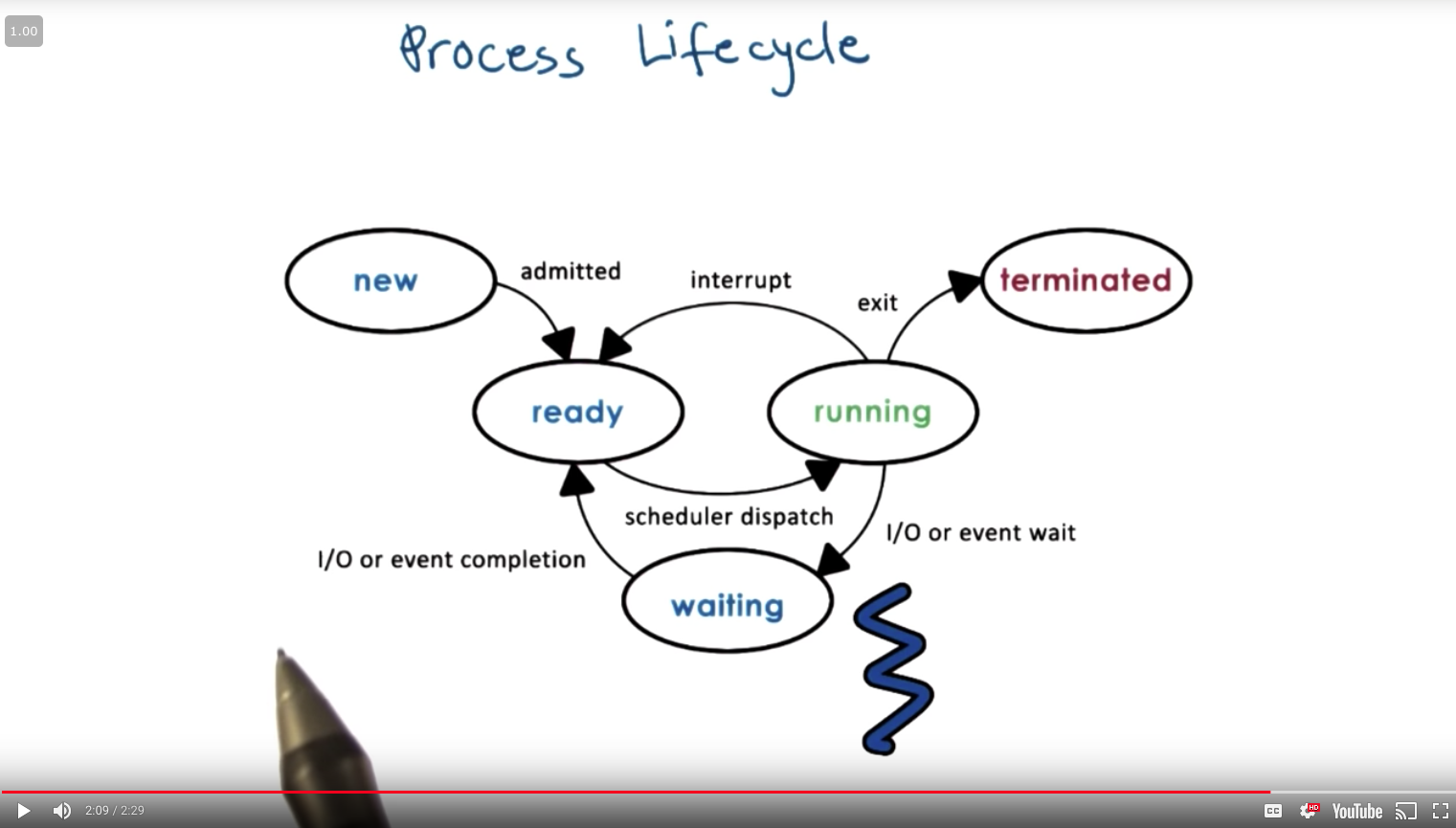

During the context switch discussion, we said that P1 and P2 were going back and forth between running and idling. So they were in two states. They were either running or idling. When a process is running, it can be interrupted and context-switched. At this point, the process is idle, but it’s in what we call a ready state. It is ready to execute, except it is not the current process that is running from the CPU. At some later point, the scheduler would schedule that process again, and it will start executing on the CPU, so it will move into the running state. What other states can a process be in? And how is that determined? To answer that question, let’s look at a general illustration of the states that a process is going through throughout its life cycle. Initially, when a process is created, it enters the new state. This is when the OS will perform admission control, and if it’s determined that it’s okay, the operating system will allocate and initiate a process control block and some initial resources for this process. Provided that there are some minimum available resources, the process is admitted, and at that point, it is ready to start executing. It is ready to start executing, but it isn’t actually executing on the CPU. It will have to wait in this ready state until the scheduler is ready to move it into a running state when it schedules it on the CPU. So, once the scheduler gives the CPU to a ready process, that ready process is in the running state. And from here, a number of things can happen. First, the running process can be interrupted so that a context switch is performed. This would move the running process back into the ready state. Another possibility is that a running process may need to initiate some longer operation, like reading data from disk or to wait on some event like a timer or input from a keyboard. At that point, the process enters a waiting state. When the event occurs or the I/O operation completes, the process will become ready again. Finally, when a running process finishes all operations in the program or when it encounters some kind of error, it will exit. It will return the appropriate exit code, either success or error, and at that point, the process is terminated.
16 - Process State Quiz¶

Let’s take a quiz now. Using the process life cycle diagram, let’s answer the following question. The CPU is able to execute a process when the process is in which of the following states? You’ll need to check all that apply and here are the choices. Running, ready, waiting, or new.
17 - Process State Quiz Solution¶
A running process is already executing, so it should be marked as a correct answer. Any of the processes that are in ready state, the CPU is able to execute them. They’re just waiting for the operating system’s scheduler to schedule them on the CPU. You should remember that as soon as a ready process is scheduled on the CPU, it will continue its execution from the very first instruction that’s pointed by the process program counter. It is possible that this is the very first instruction in the process, if the process entered the ready queue for the first time after being newly created. And the other option is that it’s some other random instruction in the process binary, depending on when the process was interrupted last time. Either when it was interrupted by the scheduler or because it had to stop executing since it had to wait on an I/O or some kind of external event.
18 - Process Life Cycle: Creation¶

You may be asking yourself, how are processes created? What came first? In operating systems, a process can create child processes. In this diagram here, you see that all processes will come from a single root, and they will have some relationship to one another where the creating process is the parent and the created process is the child of that parent. Some of these will be privileged processes. They will be root processes. In fact, this is how most operating systems work. Once the initial boot process is done and the operating system is loaded on the machine, it will create some number of initial processes. When a user logs into a system, a user shell process is created. And then when the user types in commands, like list or emacs, then new processes get spawned from that shell parent process. So the final relationship looks like this tree. Most operating systems support two basic mechanisms for process creation, fork and exec. A process can create a child via either one of these mechanisms. With the fork mechanism, the operating system will create a new Process Control Block for the child. And then it will copy the exact same values from the parent Process Control into the child Process Control Block. At that point, both the parent and the child will continue their execution at the instruction that’s immediately after the fork. And this is because both the parent and the child have the exact same values in their Process Control Block, and this includes the value of the program counter. So, after the operating system completes the fork, both of these processes will start their execution at the exact same point. Exec behaves differently. It will take a Process Control Block structure created via fork, but it will not leave its values to match the parent’s values like with fork. Instead, the operating system place the child’s image. It will load a new program. And the child’s PCB will now point to values or describe values that describe this new program. In particular, the program counter for the child will now point to the first instruction of the new program. Now, the behavior of actually creating a new program is like, you call a fork, where the fork creates the initial process. And then you call an exec, which replaces the child’s image, the image that was created in the fork, with the image of this new program.
19 - Parent Process Quiz¶

Since we have been talking about process creation, let’s take a quiz about some special parent processes. The first question is, on UNIX-based operating systems, which process is often regarded as the parent of all processes? And the second question, which is not required but it’s extra credit, on the Android OS, which process is regarded as the parent of all App processes? Feel free to use the Internet to find the answer for these questions
20 - Parent Process Quiz Solution¶
On UNIX-based systems, init is the first process that starts after the system boots. And because all other processes can ultimately be traced to init, it’s referred to as the parent of all processes. On the Android OS, Zygote is a daemon process which has the single purpose of launching app processes. The OS accomplishes this by forking the Zygote process every time a new app needs to be created, so the Zygote process is the parent of all of the apps.
21 - Role of the CPU Scheduler¶

Let’s talk about process scheduling next. For the CPU to start executing a process, the process must be ready first. The problem is, however, there will be multiple ready processes waiting in the ready queue. How do we pick what is the right process that should be given the CPU next, that should be scheduled on the CPU? This is a simple diagram where we have our ready queue with several processes waiting in it. Here’s the CPU which has currently one process scheduled on it. So the question is, which process do we run next? This is determined by a component called a CPU scheduler. The CPU scheduler is an operating system component that manages how processes use the CPU resources. It decides which one of the currently ready processes will be dispatched to the CPU so that it can start running, start using the CPU. And it also determines how long this process should be allowed to run for. Over time this means that in order to manage the CPU, the operating system must be able to preempt, to interrupt the executing process and save its current context. This operation is called preemption. Then the operating system must run the scheduling algorithm, in order to choose one of the ready processes that should be run next. And finally, once the process is chosen, the OS must dispatch this process on to the CPU and switch into its context so that process can finally start executing. Given that the CPU resources are precious, the operating system needs to make sure that CPU time is spent running processes and not executing scheduling algorithms and other operating system operations. So, it should minimize the amount of time that it takes to perform these tasks. The operating system must be efficient in that respect. What that means is that it is important to have both efficient designs as well as sufficient implementations of the various algorithms that are used, for instance in scheduling. As well as efficient data structures that are used to represent things like the waiting processes or any information that’s relevant to make scheduling decisions. This includes information about the priority of the processes, about their history, like how long that they ran in the past, other information may be also useful.
22 - Length of Process¶

Another issue to consider is how often do we run the scheduler? The more frequently we run it the more CPU time is wasted on running the scheduler versus running application processes. So, another way to ask this same question is how long should a process run? The longer we run a process, the less frequently we are invoking the scheduler to execute. Consider this scenario in which we are running processes for amount of time Tp, and the scheduler takes some amount of time Tsched to execute. If you want to understand how well the CPU was utilized, we have to divide the total processing time that was performed during an interval. So during this interval that was 2 times Tp and then divide that by the total duration of the interval. So the total duration of the interval is 2 times Tp plus 2 times the scheduling interval. If the processing time and the scheduling time are equal as in this picture, that means that only 50% of the CPU time is spent on useful work. Half of the time during this interval, the CPU was basically doing systems processing work, scheduling, and that time should be considered overhead. Let’s now look at the second interval, where the processing time Tp is much larger than the scheduling time. And let’s assume that it’s actually 10 times the scheduling time, not to scale. So if we work out the math here, we will find out that almost 91% of the CPU time was spent on actually doing useful work. So we’re doing much better in this interval in terms of the efficiency of the CPU. How much of it is used for useful application processing versus in this previous time. In these examples, Tp refers to the time that’s allocated to a process that has been scheduled to run. And so the time that that process can consume on the CPU. We refer to this time as the timeslice. As you can see there are a lot of decisions and tradeoffs that we must make when we’re considering how to design a scheduler. Some of these include deciding what are appropriate timeslice values for instance, or deciding what would be good metrics that are useful when the scheduler is choosing what’s the next process it should run. I will discuss these design issues in a later lesson. But for now you need to be aware that some decisions need to be made.
23 - What about I/O¶


Before we move forward, we need to consider how I/O operations affect scheduling. So far, we know the operating system manages how processes access resources on the hardware platform. And this in addition to the CPU and memory will include I/O devices, peripherals like keyboards, network cards, disks, et cetera. So in this diagram, imagine a process had made an I/O request. The operating system delivered that request. For instance, it was a read request to disk. And then plays the process on the I/O queue that’s associated with that particular disk device. So the process is now waiting in the I/O queue. The process will remain waiting in the queue until the device completes the operations, so the I/O event is complete, and responds to that particular request. So once the I/O request is met, the process is ready to run again, and depending on the current load in the system, it may be placed in the ready queue. Or it may be actually scheduled on the CPU if there’s nothing else waiting in the ready queue before it. So to summarize, a process can make its way into the ready queue in a number of ways. A process which was waiting on an I/O event ultimately found its way into the ready queue. A process which was running on the CPU, but its time slice expired goes back on the ready queue. When a new process is created via the fork call, it ultimately ends its way on the ready queue. Or a process which is waiting for an interrupt, once the interrupt occurs, it will also be placed on the ready queue.
24 - Scheduler Responsibility Quiz¶

To make sure you understand the responsibilities of a CPU scheduler, let’s take a quiz. The question is, which of the following are not a responsibility of the CPU scheduler? The options are, maintaining the I/O queue, maintaining the ready queue, deciding when to context switch, or deciding when to generate an event that a process is waiting on. You should pick all that apply.
25 - Scheduler Responsibility Quiz Solution¶
Let’s see what the correct answers are. So which of the following are not a responsibility of the scheduler? First, the scheduler has no control over when I/O operations occur. So clearly the first choice should be marked. One exception are the timer interrupts. Depending on the scheduling algorithm, the scheduler chooses when a process will be interrupted, so when it will context switch, so clearly it has some influence over when events based on the timer interrupt will be generated. This also answers the third question. It is the scheduler, based on the scheduling algorithm, that decides when a process should be context switched, so this clearly is responsibility of the scheduler. Similarly, it is the scheduler that’s in charge of maintaining the ready queue. It is the one that decides which one of the processes in the ready queue will be scheduled to execute next. And finally, the scheduler really has no control over when external events can be generated, other than the timer interrupt as we discussed. So it has no control over events that a process may be waiting on. So this choice should be marked as well.
26 - Inter Process Communication¶



Another natural question can be, can processes interact? And the simple answer to this is yes. An operating system must provide mechanisms to allow processes to interact with one another. And today in fact, more and more of the applications we see are actually structured as multiple processes. So these multiple processes have to be able to interact to contribute to a common goal of a more complex multi-process application. For instance, here’s an example of a web application consisting of two processes on the same machine. The first one is the web server, the front-end, that accepts the customer request. And the second one is the backend, the database that stores customer profiles and other information. This is a very common case in many enterprise and web applications. So, how may these processes interact? Now, before we answer that, remember that the operating systems go through a great deal to protect and isolate processes from one another. Each of them is a separate address space. They control the amount of CPU each process gets, which memory is allocated, and accessible to each process. So these communication mechanisms that we will talk about somehow have to be built around those protection mechanisms. These kinds of mechanisms are called inter-process communication mechanisms, or we refer to them as IPC. The IPC mechanisms help transfer data and information from one address space to another, while continuing to maintain the protection and isolation that operating systems are trying to enforce. Also, different types of interactions between processes may exhibit different properties. Periodic data exchanges, continuous stream of data flowing between the processes or coordinated at the, to some shared single piece of information. Because of all these differences, IPC mechanisms need to provide flexibility as well as clearly performance. One mechanism that operating systems support is message passing IPC. The operating system establishes a communication channel, like a shared buffer for instance, and the processes interact with it by writing or sending a message into that buffer. Or, reading or receiving a message from that shared communication channel. So, it’s message passing because every process has to put the information that it wants to send to the other process, explicitly in a message and then to send it to this dedicated communication channel. The benefits of this approach is that it’s really the operating system who will manage this channel, and it’s the operating system that provides the exact same APIs, the exact same system calls for writing or sending data, and the reading or receiving data from this communication channel. The downside is the overhead. Every single piece of information that we want to pass between these two processes we have to copy from the user space of the first process into this channel that’s sitting in the OS, in the kernel memory. And then back into the address space of the second process. The other type of IPC mechanism is what we call shared memory IPC. The way this works is the operating system establishes the shared memory channel, and then it maps it into the address space of both processes. The processes are then allowed to directly read and write from this memory, as if they would to any memory location that’s part of their virtual address space. So the operating system is completely out of the way in this case. That in fact is the main advantage of this type of IPC. That the operating system is not in the fast path of the communication. So the processes, while they’re communicating are not going to incur any kind of overheads from the operating system. The disadvantage of this approach is because the operating system is out of the way it no longer supports fixed and well defined APIs how this particular shared memory region is used. For that reason, its usage sometimes becomes more error prone, or developers simply have to re-implement code to use this shared memory region in a correct way.
27 - Shared Memory Quiz¶

Let’s provide a little bit of more information through this shared memory quiz. Let’s look at this statement. Shared memory-based communication performs better than message passing communication. So, you think this statement is true? It is false? Or, whether it depends on something
29 - Lesson Summary¶

In this lesson, we’ll learned how a process is represented by operating systems. We learned how process is laid out in memory, how operating systems use the process control block structure to maintain information about a process during its lifetime. We looked at some of the key mechanisms that operating systems support to manage processes, like process creation and process scheduling. And then finally, we reviewed some aspects of memory management that are necessary for your understanding of some of the decisions and overheads that are associated with process management.
30 - Lesson Review¶
As the final quiz, please tell us what you learned in this lesson. Also, we’d love to hear your feedback on how we might improve this lesson in the future.